Pipeline
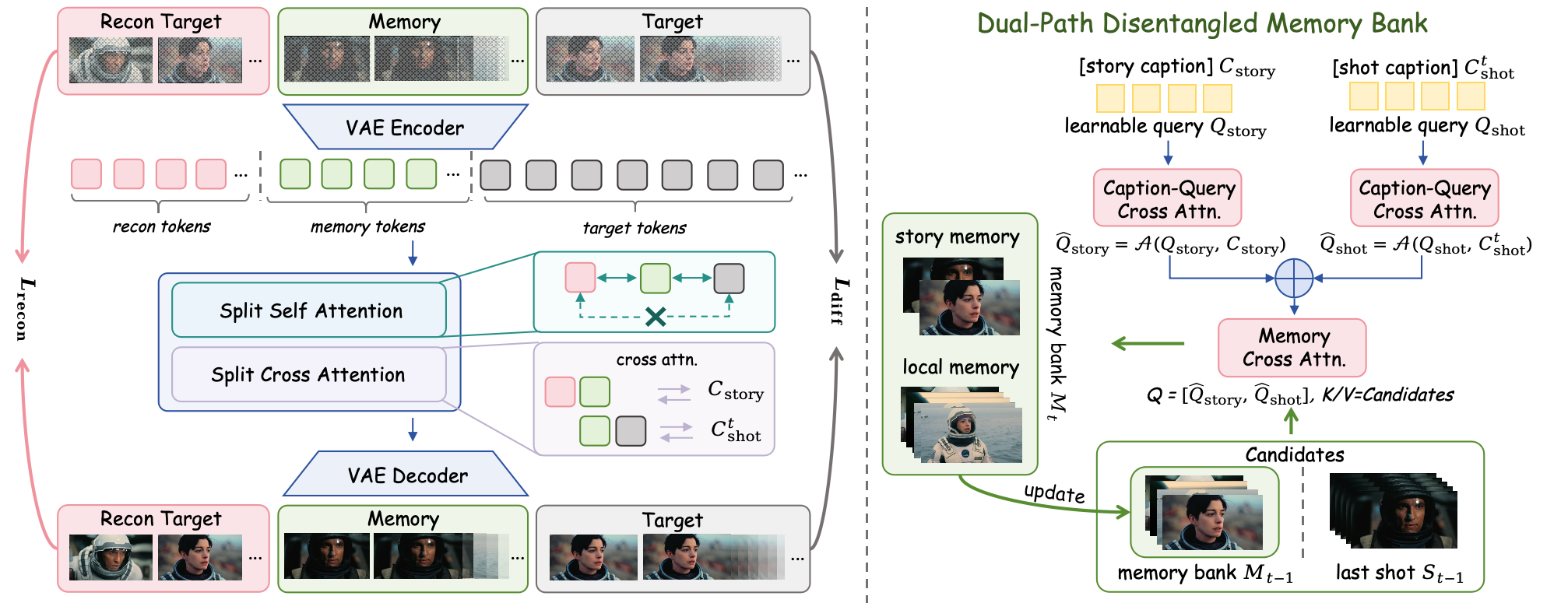
Overview of our framework. We employ split self-attention over overlapping local groups, allowing reconstruction–memory and memory–target interactions while avoiding full global attention. Split cross-attention injects both global story-level and local shot-level captions. Story and shot captions condition separate learnable queries via caption-to-query cross-attention. The fused query retrieves relevant candidates from the memory bank and the last shot, and updates global and local memory states for scalable long-form generation.